长久以来,简单的多票制被广泛用在基层班团各种差额推优上面。然而,这一制度是否合理呢?
进入大学以来,每学期都要参与那么几次投票:选班干部、推党校、定三好学生……投票参加的多了,各种情景都遇得到,像是台上候选人一个都不熟,但非要硬着头皮选一个的情况也时有发生。这种情况并不少见。在行政班级越来越形同虚设的现代大学之中,同班同学不一定是相互熟悉的、相互熟悉的不一定是同班同学。这种社交圈和行政建制的错配,让投票越发处于一个尴尬的地位:一方面,它的确是相对公平的推优方式,同时集体决策也有利于责任分散,不至于让推优的组织者承担什么责任;但另一方面,相互不了解的同学之间本就缺乏评价的基础,在本就没有偏好的情况下强行投票,其产生的噪声很容易淹没真正有价值的信息。
有人可能会说:不了解的同学不参加投票不就好了吗?的确,这是一种理想的解决方法。但现实中,“弃权”很容易被解释为“无声的反对”。而且相比没投某个候选人,弃权总是更显眼的(投票是匿名的,弃权却要站出来)。所以现实操作中,很少有人主动出这个头,惹这些麻烦。
这就引出了一个问题:现行多票制下的票差到底是投票者随便投产生的随机误差,还是说真的存在稳定的偏好关系?
无偏好假设下的票数分布分析
考虑一个包含 n 名候选人、m 名选民的投票场景,其中每位选民投 k 票。在”选民对候选人 i、j 无真实偏好”的假设下,每个选民对二者票差的贡献可视为随机变量:
$$ X= \begin{cases} 1 & \text{投 } i \text{ 不投 } j\\ -1 & \text{投 } j \text{ 不投 } i\\ 0 & \text{其他,即两者均不投} \end{cases} $$
因此,候选人 i 与 j 的总票数差为:
$$ D_{ij} = V_i - V_j = \sum_{t=1}^m X_t $$
在“无偏好”假设下有 $$ \mathbb E[D]=0 $$ 下面计算单个选民贡献的方差。
我们知道
$$ P(X=1) = P(i被选) × P(j不选|i被选)=\frac{k}{n} \times \frac{n-k}{n-1} $$
由对称性,有 $P(X=-1) = \frac{k}{n} \times \frac{n-k}{n-1}$
利用常见结论 $Var(X) = E(X^2) - (E(X))^2$,
$$ \mathrm{Var}(X)=2\cdot \frac{k(n-k)}{n(n-1)} $$
所以总票差的方差是
$$ \mathrm{Var}(D)=m\cdot \frac{2k(n-k)}{n(n-1)}. $$
因此当选民不太少的时候,根据中心极限定理,该票差可近似为正态分布
$$ D_{ij} \sim N\left(0,\, m\cdot \frac{2k(n-k)}{n(n-1)}\right) $$
基于上述分布,我们可以建立统计显著性判据。若票数差满足
$$ |V_i - V_j| > z \cdot \sqrt{\frac{2mk(n-k)}{n(n-1)}} $$
则可以在给定置信水平下认为选民对候选人 i、j 存在真实偏好,而非随机波动。例如,在 90% 置信水平下 z = 1.645,在 95% 置信水平下 z = 1.96。
案例分析
以上分析停留在理论阶段。现实中,上述无偏好的投票结果是否普遍呢?下面我们以笔者所在班级的两次投票结果进行检验。
案例 1:院党校推优
案例一发生在刚刚过去的2026年3月。在这次院党校推优中,共有 4 名候选人竞争 2 个名额,27 名选民参与投票,得票情况分别为 20、14、12、8 票。
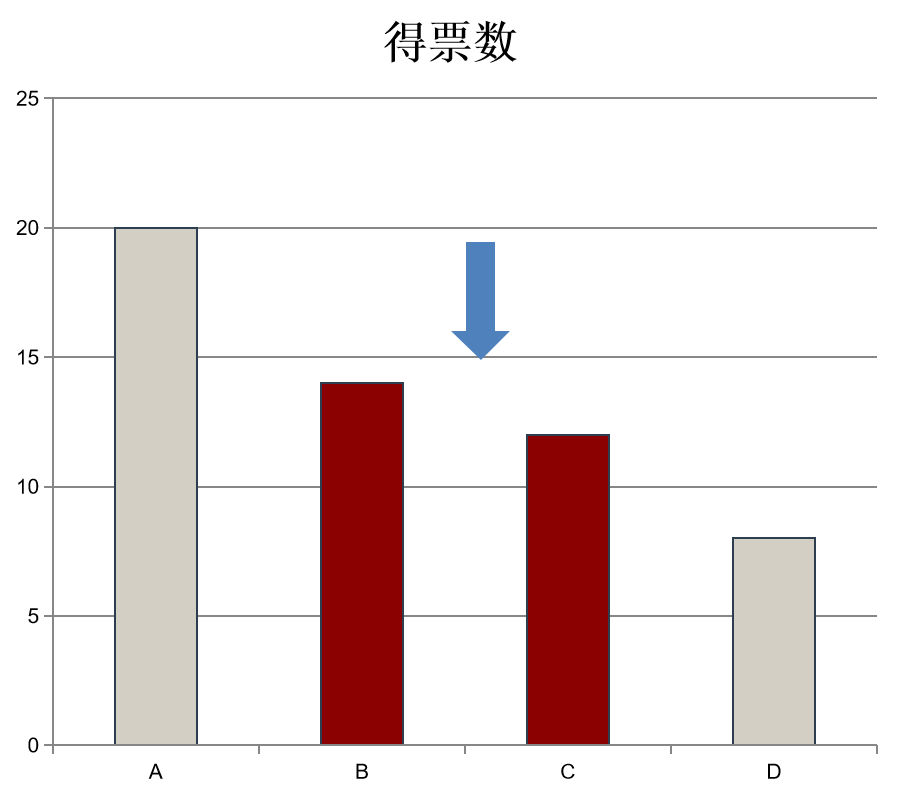
我们重点分析决定入选与否的关键边界,即第 2 名与第 3 名之间的差距。
实际票数差为 $14 - 12 = 2$ 票。根据前述公式计算标准差:$\sigma = \sqrt{\frac{2\times27\times2\times2}{4\times3}} = \sqrt{18} \approx 4.24$。在 90% 置信水平下,显著性阈值为 $1.645 \times 4.24 \approx 6.98$。
由于实际票数差 2 远小于阈值 7,该差距完全不显著。从统计学角度,我们无法认为第 2 名优于第 3 名。事实上,第二名和最后一名之间的距离也只有7票,同样没有充足证据表明这二者之间存在显著区别。
案例 2:校党校推优
案例二发生在去年12月。在这次校党校推优中,共有 7 名候选人竞争 4 个名额,25 名选民参与投票,得票情况分别为 23、15、14、14、12、11、11 票。同样分析关键边界,即第 4 名与第 5 名之间的差距。
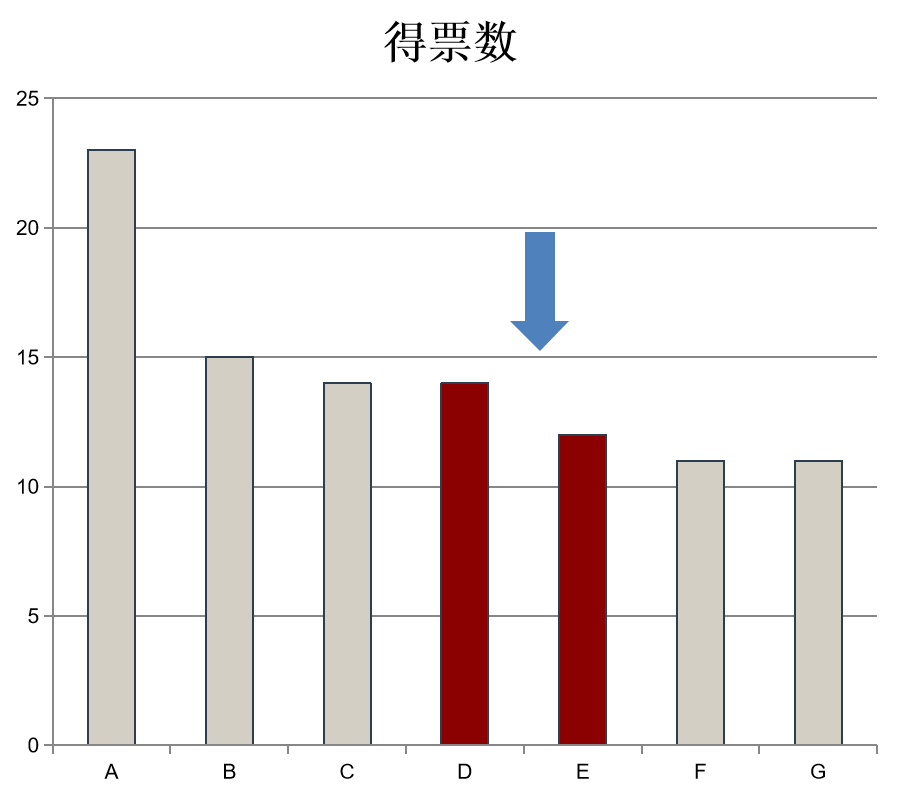
实际票数差为 $14 - 12 = 2$ 票。计算标准差:$\sigma = \sqrt{\frac{2\times25\times4\times3}{7\times6}} \approx 3.78$。在 90% 置信水平下,显著性阈值为 $1.645 \times 3.78 \approx 6.22$。
同样地,实际票数差 2 远小于阈值 6.22。且除了第一名同学得票显著较高以外,其他候选人在统计学意义上没有显著区别。
总结
这两个真实案例充分说明,在现行制度下,决定入选与否的关键边界往往落在”统计不可区分区间”内。换言之,投票结果给出了明确的排名,但这一排名在统计上并不可靠。
改进的推优方案
基于上述分析,笔者认为以候选人数量为依据可以实行两类选举方案。对于候选人较少的情况(不超过 6 人),可以直接采用排序投票制,由每位选民对所有候选人进行完整排序,从而获取选民的完整偏好信息,避免信息损失。
对于候选人较多的情况,建议采用”两轮投票制”。第一轮沿用现行的多票制,目的是快速筛选出大致范围;第二轮仅针对”争议区间”内的候选人,通过排序投票进行精细比较,确保结果的统计可靠性。这一设计的核心思想是:用低成本投票筛选大致范围,用高信息投票解决关键不确定性。

多票制的显著性筛选方法
这一方法对应两轮投票的第一轮筛选,目的是快速缩减候选人个数。
我们假设录取名额为 r,记 $V_{(r)}$ 为第 r 名(最后入选者)的票数,$V_{(r+1)}$ 为第 r+1 名(第一落选者)的票数,T 为根据置信水平计算的显著性阈值。
对于任意候选人 a,其票数 $V_a$ 可按以下规则分类: $$ \begin{cases} V_a > V_{(r+1)} + T & \text{确定入选}\\ V_a < V_{(r)} - T & \text{确定落选}\\ \text{否则} & \text{进入争议区,需第二轮投票} \end{cases} $$
即票数显著高于上界者稳定入选,票数显著低于下界者稳定落选,而中间区域在统计上无法区分,属于”模糊区”。对于落入”模糊区”的候选人,必须进入第二轮排序投票,不得仅凭第一轮票数强行排序。
例如,在一个有20个选民和20个候选人中,名额为5的差额选举中,其示意图如下。
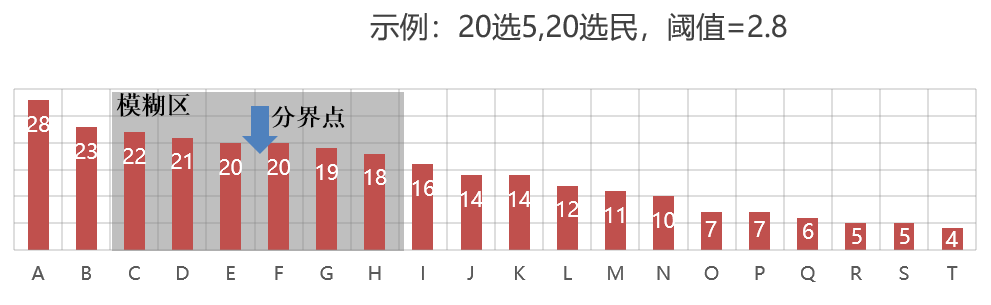
排序票的实施方法
排序票在候选人少的情况下可以直接实施,或者经由多票筛选第二轮开展。排序票一般通过对候选人之间两两竞赛(例如对候选人A, B,如果更多选民将A排在前面,那么A胜出),统计出最后的赢家。
然而无论如何,排序票都面临以下两个问题的挑战。
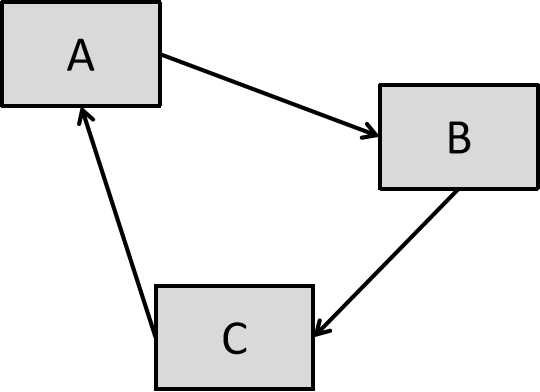
其一是循环偏好问题。如图所示,A赢了B,B赢了C,但是C又赢了A。这让偏好的传递性公理不再成立,造成了BUG。
其二是这种方式也会受到不显著问题的影响。如图,虽然D看上去是最后的赢家(无入边),但实际上D对A和B的结果都不稳。在这种情况下认为D好过A,B,C这三个有稳定偏好关系的候选人可能不公平。
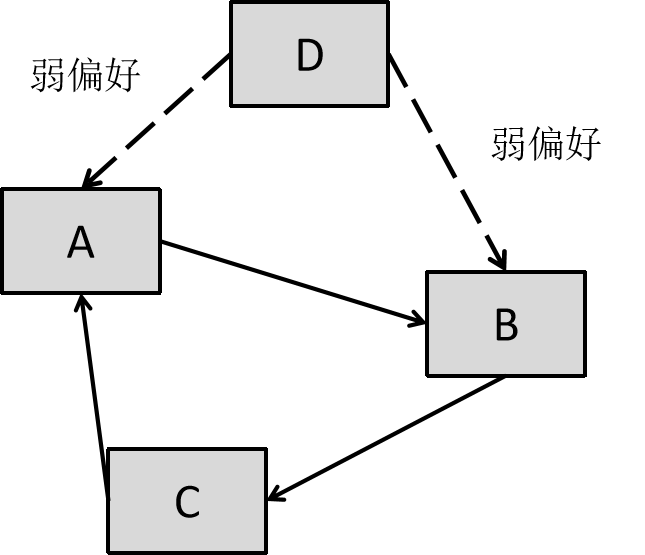
为了从理论上解决排序票的这些问题,我们可以按照这个方式操作:
1. 基本原理
在排序投票中,每位选民对候选人进行完整排序。对于任意两位候选人 i、j,我们统计 $D_{ij} = \#(i \succ j) - \#(j \succ i)$,其中 $\#(i \succ j)$ 表示”将 i 排在 j 前面”的选民人数。
与多票制不同,排序投票中每位选民对任意候选人对 (i, j) 的贡献是确定的:要么将 i 排在 j 前(贡献 +1),要么将 j 排在 i 前(贡献 -1)。在”选民对 i、j 无真实偏好”的假设下,每位选民以 50% 的概率选择任一顺序,因此 $D_{ij}$ 可视为 m 个独立的 ±1 随机变量之和。根据中心极限定理,$D_{ij}$ 近似服从正态分布 $N(0, m)$,标准差为 $\sqrt{m}$。
因此,若满足 $D_{ij} > z\sqrt{m}$(其中 z 为置信水平对应的临界值,如 90% 置信水平下 z = 1.645),则可以在给定置信水平下认为候选人 i 显著优于候选人 j。
2. 构建偏好关系图与最优排序
基于显著性检验,我们可以构建偏好关系图:若 $D_{ij} > T$(显著性阈值),则在图中连接有向边 $i \to j$,表示 i 显著优于 j。接下来的目标是找到一个排序 $\pi$,使其与偏好关系图最大程度一致。具体而言,我们希望最大化目标函数
$$ \sum_{i\to j} w_{ij} \cdot \mathbf{1}[\pi(i)<\pi(j)], $$
其中权重 $w_{ij} = D_{ij} - T$意义是偏好关系的”强度”。
这一问题可以通过整数规划求解。
定义二元变量 $$ x_{ij}= \begin{cases} 1,& i \text{ 排在 } j \text{ 前}\\ 0,& i \text{ 排在 } j \text{ 后} \end{cases} $$ 表示”候选人 i 是否排在 j 前面”。
约束条件包括完全性 $x_{ij}+x_{ji}=1$ 和传递性 $x_{ij}+x_{jk}+x_{ki} \le 2$,优化目标为
$$ \max \sum_{i,j} w_{ij} \cdot x_{ij} $$
这样设计的核心思想在于:寻找违背偏好关系最少的那个方案作为最终的竞选结果。如下面所示,
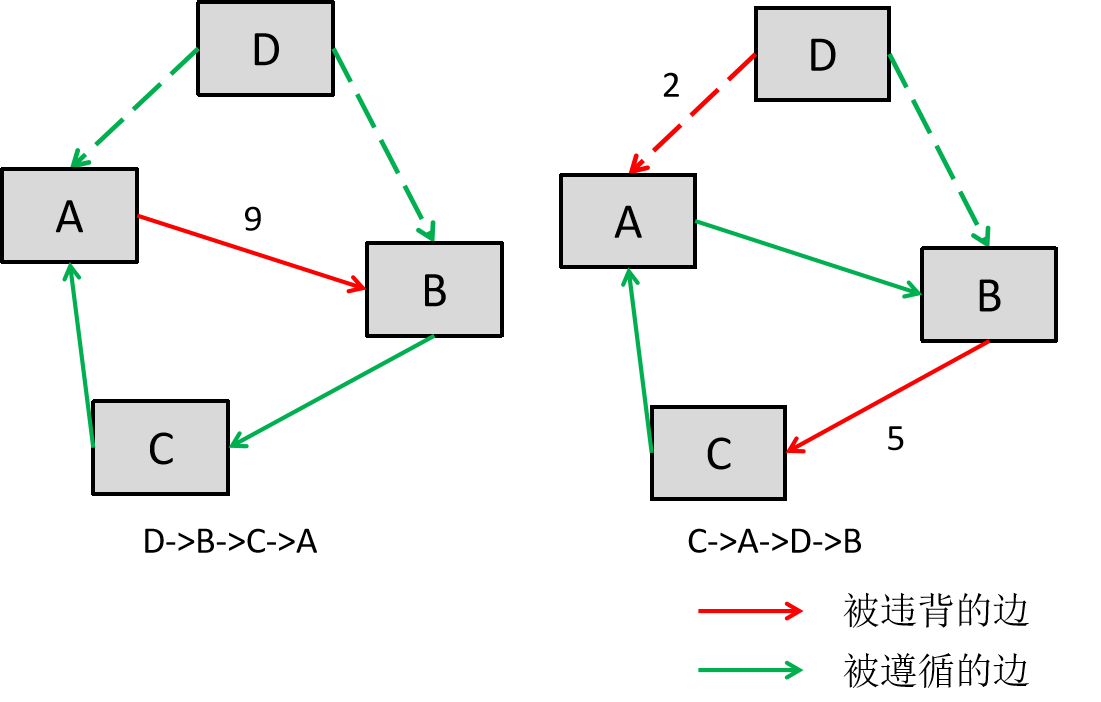
左边方案将D作为第一,其造成了分值为9的违背;右边方案虽然看上去违背了更多的关系,然而因为违背的关系没有那样稳固,因此这种情况下只造成了7点违背。因此右边的方案比左边的方案更好。这样一来,循环偏好问题及弱显著性问题就被一并解决了。
使用计算机求解上述问题并不困难,可以使用枚举的方式,亦可使用可使用整数规划求解器(如Gurobi)进行求解。这些技术细节在这里就略去不表了。
总结与展望
这个提议的核心思想是用统计显著性识别不确定性,用高信息投票解决不确定性。具体而言,我建议引入统计显著性检验,避免”随机波动决定结果”的情况,确保入选者确实获得更多认可;识别”统计模糊区”,承认数据的局限性,避免对无法区分的候选人强行排序;对争议候选人采用排序投票,获取更完整的偏好信息,提高决策的可靠性;运用数学优化方法,基于偏好关系图构建最优排序,使结果更加合理、可信。
不过虽然在学理上是可行的,在现实实施中至少会遇到这样的问题。第一个是置信区间怎么选择。是95%,90%甚至是85%,这都给人为操作选举结果留下了空间。另外,尽管在代码智能体已经相当成熟的现在,编程这件事还是有一定门槛的,尤其是对大部分RUC本科生而言。如果最后的排序票需要程序实现,对一些人而言可能就成了事实上的黑箱,带来信任成本。
基于这样的考量,上述想法目前也只是一个想法,希望能够引起大家的思考。不过一个结论是明确的:现行多票制的确存在随机误差吞没真实抉择的情况。既然问题存在,那么我们就必须正视问题,尝试解决,而不是对此视而不见。
后记:成稿后,笔者向所在学院的团组织和党组织同时提交了正式的建议,在一天之内竟都收到了认真的答复。团委老师还邀请笔者当面交流看法诚然,这份意见离一份真正可落地的政策还有不远的距离,但校内党团言路畅通的状态是让人欣喜的。